
AWS 모니터링
모니터링은 서비스를 계속해서 실행할 수 있게 해주는 중요한 기능 중 하나
AWS CloudWatch Metrics
- CloudWatch는 AWS 모든 서비스에 지표를 제공
- 지표(metric)은 모니터링 할 지표
- CPU 사용률, networkin, bucket size…
- 지표는 네임스페이스에 속하기 때문에 각기 다른 네임스페이스에 저장
- 서비스당 네임스페이스는 하나이다
- 지표의 속성으로 측정 기준(Dimension)이 있다
- instance id, enviroment…
- 지표당 최대 측정 기준은 10개
- 타임스탬프
- 지표가 많아지면 CloudWatch 대시보드에 추가해 모든 지표를 한 번에 볼 수 있다
- 사용자 지정 지표를 만들수도 있다
- 메모리 사용량 추출 등..
- 다양한 GUI로 확인 가능
CloudWatch Metric Stream
- CloudWatch 외부로 스트리밍 할 수 있다
- 거의 실시간 전송 + 지연시간또한 짧다
- Firehose.. 원하는 곳(서드파티 또한 가능)
- 지표 또한 네임스페이스 등으로 필터링 가능
- 필터링 지표의 서브셋만 Firehose로 전송 가능
CloudWatch Logs
- 로그 그룹: 로그들을 로그 그룹으로 그룹화 → 로그 그룹의 이름으로는 애플리케이션을 나타냄
- 로그 스트림: 로그 그룹에는 로그 스트림이 있고 애플리케이션 내 인스턴스나 다양한 로그 파일명 또는 컨테이너를 나타낸다
- 로그 만료 기한도 정할 수 있다
- S3, Kinesis Data Streams, Firehose, AWS Lambda, Elastic Search등으로 보낼 수 있다
CloudWatch Logs - Sources
- SDK, CloudWatch Logs Agent(요즘사장되는 추세), Cloud Watch Unified Agent
- Elastic Beanstalk: 애플리케이션 로그를 CloudWatch로 전송
- ECS: 컨테이너의 로그를 전송
- Lambda: 함수 자체에서 로그를 보낸다
- VPC Flow Logs: VPC 메타데이터 네트워크 트래픽 로그를 보낸다
- API Gateway: 받는 모든 요청을 보낸다
- CloudTrail: 필터해서 보낸다
- Route53: 모든 DNS 쿼리를 로그로 저장
CloudWatch Logs Metric Filter & Insights
- CloudWatch Logs에서 필터 표현식을 쓸 수 있다
- 로그 내 특정 IP를 찾을 수 있거나 로그 중 “ERROR” 메시지가 들어있는 로그를 찾을 수 있음
- Metric Filter를 통해 출현 빈도를 계산해 지표를 만들 수 있다
- CloudWatch 알람 트리거로도 사용할 수 있음
- CloudWatch Logs Insights → 로그를 쿼리하고 쿼리를 대시보드로 추가 가능
- 이를 통해 빠른 검색과 효율적인 분석이 가능
S3 Export
- Export까지 최대 12시간
- 실시간이 아니기 때문에 로그를 스트림하고 싶다면 Log Subscriptions를 사용해야 한다

CloudWatch Logs Subscriptions
- CloudWatch 위에 적용하여 로그를 목적지로 보내는 필터
- S3로 내보내는 방법보다 훨씬 빠르다

CloudWatch Logs Aggregation Multi-Account & Multi Region
- 모든 로그를 한 곳에서 모을 수 있음

CloudWatch Logs for EC2
- ec2에서 CloudWatch로는 어떠한 로그도 옮겨지지 않는다
- 에이전트라는 작은 프로그램을 실행시켜 원하는 로그파일을 푸시해야함
- ec2 인스턴스에 IAM Role을 추가해줘야한다
- 온프레미스 서버환경에서도 서비스 제공이 가능하다

CloudWatch Logs Agent & Unified Agent
- 두가지 모두 온프레미스 서버같이 가상 서버를 위함(EC2, 온프레미스 서버)
Logs Agent
- 더 오래된 버전의 Agent
- CloudWatch Log로만 로그를 보낼 수 있다
Unified Agent
- 프로세스나 RAM같은 추가적인 시스템 단계 지표를 수집
- 지표와 로그를 둘 다 사용하기 때문에 통합이라는 unified가 붙는다
- CloudWatch log로 로그를 보냄
- SSM Parameter Store를 통해 에이전트를 쉽게 구성 가능
- 모든 통합 에이전트를 모아 중앙 집중식 환경 구성을 할 수 있다
Unified Agent - Metrics
인스턴스나 리눅스 서버를 만들면 지표 정보를 직접적으로 가져올 수 있다
지표 정보 목록은 다음과 같다
하드웨어 소프트웨어 지표 모두 수집 가능
- CPU → (active, guest, idle, system, user, steal)
- Disk metrics → (free, used, total), 디스크 I/O (writes, reads, bytes, iops)
- RAM → (free, inactive, used, total, cached)
- 넷 상태(Netstat) → (number of TCP and UDP connections, net packets, bytes)
- 프로세스 → (total, dead, bloqued, idle, running, sleep)
- 스와프 공간 → (Swap Space) (free, used, used %)
Unified CloudWatch Agent가 기본 ec2 인스턴스 모니터링보다 훨씬 더 많은 정보와 세부적인 지표를 뽑을 수 있다.(기본 모니터링은 포괄적인 정보만 알 수 있음)
CloudWatch Alarms
- 지표에서 알림을 트리거할 때 사용한다
- sampling, %, max, min 등의 다양한 옵션을 추가해서 복잡한 경보 정의 가능
- 알람 상태
- OK → 트리거되지 않은 안정 상태
- INSUFFICIENT_DATA → 상태를 결정할 데이터가 부족
- ALARM → 임계값을 넘어 알람이 보내지는 상태
- Period → 경보가 지표를 살펴보는 기간
- 짧게 설정하거나 길게 설정할 수 있음
- 고해상도 사용자 지정 지표에도 적용 가능 10초 30초 60의 배수
CloudWatch Alarm Targets
- ec2 인스턴스들의 동작 → 멈추거나, 종료, 재부팅, 복구 동작
- ec2 auto scaling → 스케일 아웃, 스케일 인
- SNS → 람다함수를 통해 위반된 알람시 원하는 작업 수행
EC2 Instance Recovery
- 상태 점검
- 인스턴스 상태 → ec2 vm 상태 점검
- 시스템 상태 → 하드웨어 점검
- 두 가지 점검으로 알람을 만들 수 있다
모니터링하다가 경보가 위반됐을 때 복구를 위해 인스턴스를 다른 호스트로 옮기는 등의 작업 수행 가능
복구 작업은 같은 인스턴스 정보를 그대로 유지하며 복구가 가능

알아두면 좋은 정보
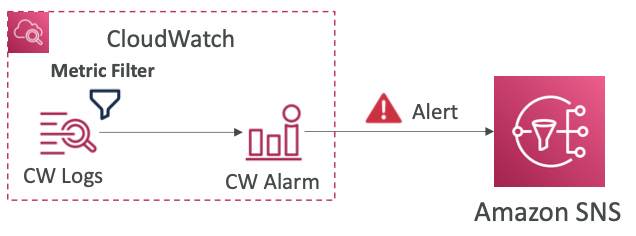
- CloudWatch Logs 지표 필터를 기반으로 알람 생성 가능
- CloudWatch Logs는 경보에 연결된 필터를 가질 수 있다
- 필터에 특정 단어가 지나치게 많이 생기면 알람을 발생시키도록 설정 가능
- set-alarm-state를 통해 경보알림테스트 가능
Amazon EventBridge
- Schedule: 클라우드에서 CRON 작업을 할 수 있게한다(스크립트를 예약함)
- Event Pattern: 특정 작업을 수행하는 서비스에 반응
- 람다를 통해 SQS, SNS등 여러 서비스로 보낼 수 있음


EventBridge Rules
- EventBridge + CloudTrail은 AWS 계정에서 생성된 모든 API 호출을 가로챌 수 있다
- 필터를 통해 특정 이벤트만 추출 가능
- JSON 문서를 생성해서 여러 정보를 담아 다양한 대상으로 전송

EventBUs의 종류
- Default Event Bus → AWS 내부
- Partner Event Bus → 파트너와 통합하여 파트너의 특정 이벤트를 이벤트 버스로 보낼 수 있음
- Custom Event Bus → 애플리케이션 자체 이벤트를 여러 대상으로 이벤트를 보낼 수 있다
- 리소스 기반 정책을 통해 다른 AWS 계정의 이벤트 버스에 엑세스할 수 있다
- 이벤트 아카이빙 또한 가능 (보존기한 또한 설정 가능)
- 아카이브된 이벤트를 다시 실행 가능

Schema Registry
EventBridge는 여러 곳에서 이벤트를 받을 수 있기 때문에 이벤트가 어떻게 생겼는지 파악해야함
- Schema Registry를 사용하면 애플리케이션의 코드를 위해 어떻게 정형화되는지 미리 알 수 있다
- 스키마 추론 가능
- 스키마 버저닝도 가능해서 스키마를 반복할 수 있음

Resource-based Policy
- 특정 이벤트 버스의 권한을 관리할 수 있다
- 다른 리전이나 다른 계정의 이벤트를 허용하도록 설정
- 여러 계정 모음인 AWS Organizations의 중앙에 이벤트 버스를 두고 모든 이벤트를 모은다

CloudWatch Insights
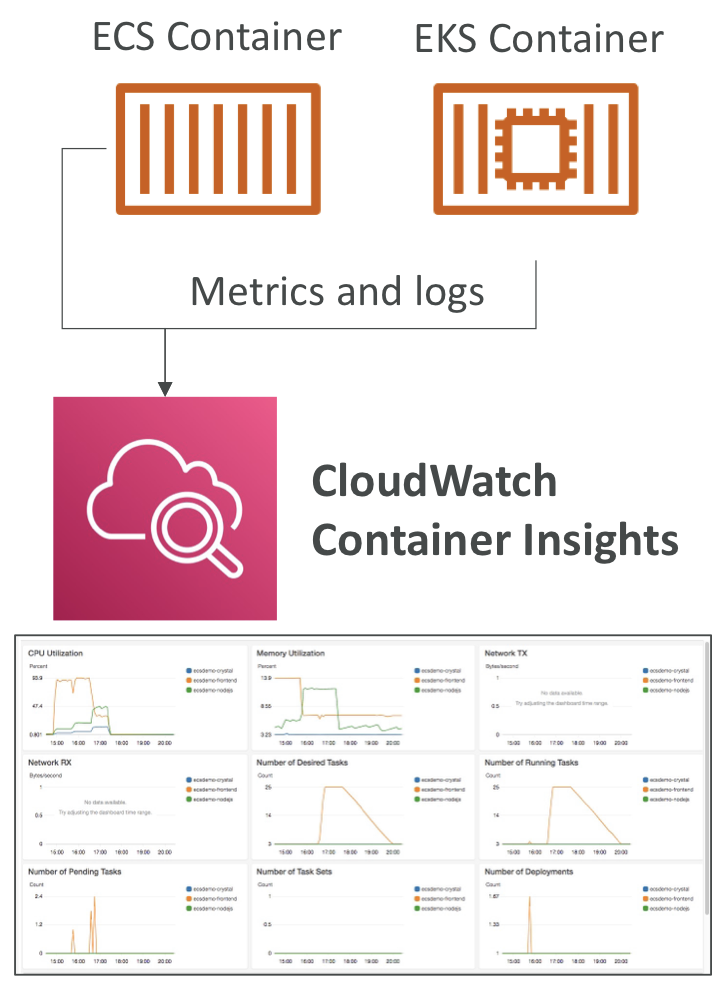
CloudWatch Container Insights
- 컨테이너로부터 지표와 로그를 수집, 집계,요약하는 서비스
- ECS, EKS 컨테이너에서 사용 가능 or Fargate
- 지표를 수집해 세분화된 대시보드를 만들 수 있다
- 컨테이너화된 버전의 CloudWatch를 실행할 에이전트를 사용해야 컨테이너를 찾을 수 있다
Lambda Insights
- Lambda에서 실행하는 서버리스 애플리케이션을 위한 모니터링과 트러블슈팅 솔루션
- CPU, 메모리 디스크, 네트워크같은 시스템 지표를 수집, 집계가 가능
- Lambda 계층으로 제공된다 → 람다 함수 옆에서 실행해서 대시보드를 생성해 성능을 모니터링
- 세부모니터링 필요시 사용

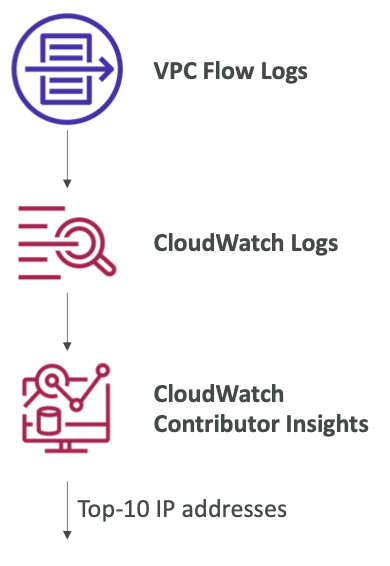
Contributor Insights
- Cloud Watch Logs를 통해 컨트리뷰터 데이터를 표시하는 시계열 데이터를 생성하고 로그를 분석하는 서비스
- 상위 컨트리뷰터에 대한 지표 확인과 총 기고자 수 및 사용량에 대한 지표 확인
- 네트워크의 상위 대화자(대상)를 찾고 시스템 성능에 영향을 미치는 대상을 파악할 수 있다
- AWS가 생성하는 모든 로그에서 동작 VPC, DNS 로그 등등..
- 불량 호스트를 식별(사용량이 가장 많은 네트워크 사용자) / 오류를 가장 많이 생성하는 URL을 찾을 수 있다.
- 규칙은 직접 생성하거나 AWS가 생성한 규칙을 활용 가능
- 백그라운드에는 CloudWatch Logs가 동작
- 다른 AWS에서 가져온 지표도 분석할 수 있다
CloudWatch Application Insights
- 애플리케이션의 잠재적인 문제와 진행중인 문제를 분리할 수 있도록 자동화된 대시보드 제공
- Java, .NET, 특정 데이터베이스 등 선택한 기술로 애플리케이션이 실행될 수 있다
- 다른 AWS 리소스와 연결 된다
- 앱에 문제가 있는 경우 자동으로 대시보드를 생성하여 잠재적인 문제를 보여준다
- 자동화된 대시보드를 생성할 때 내부적으로 SageMaker가 사용됨
- 애플리케이션 상태 가시성을 높여 트러블 슈팅이나 보수하는 시간이 줄어들 수 있다
- 문제가 생기면 자동으로 대시보드에 표시
- 발견된 문제와 알림은 모두 EventBridge랑 SSM Opscenter로 전달된다
- 문제가 생기면 알림이 온다
CloudTrail
- AWS 계정의 거버넌스, 감사 및 규정 준수를 돕는다
- 기본적으로 활성화 되어있다
- 콘솔, SDK, CLI, 기타 AWS 서비스에서 발생한 AWS 계정내의 모든 이벤트 및 API 호출기 기록을 받아 볼 수 있다 → 계정 관련 모든 로그가 CloudTrail로 간다
- CloudTrail의 로그를 CloudWatch Logs나 S3로 옮길 수 있다
- 전체 또는 단일 리전에 적용되는 트레일을 설정해 모든 리전에 걸친 이벤트 기록을 한곳으로 모을 수 있다 → S3 버킷에 저장 가능
- 누군가가 AWS에서 무언가를 삭제했을 때 확인할 수 있다
- API 호출이 남아있음
CloudTrail Diagram
- 모든 이벤트를 90일 이상 보존하려면 s3나 CloudWatch Logs로 보내면 된다

CloudTrail Events
관리 이벤트
- 리소스에서 수행되는 작업을 나타낸다
- 누군가가 보안 설정을 구성하면 IAM AttachRolePolicy라는 API를 사용하며 이것이 CloudTrail에 남는다
- 서브넷을 생성해도 표시되고 로깅을 설정해도 기본으로 표시된다
- 리소스나 AWS 계정을 수정하는 모든 작업이 CloudTrail에 표시
- Read Event와 Write Event를 분리할 수 있다
- 리소스를 수정하는 이벤트와 수정하지 않는 이벤트 → 수정하는 이벤트(write 이벤트가 중요)
데이터 이벤트
- 고볼륨작업으로 기본 옵션으로 설정되지 않는다
- s3 버킷에 GetObject, DeleteObject, PutObject 등은 많이 수행되는 작업이므로 기본적으론 로깅되지 않는다.
- 읽기 이벤트와 쓰기 이벤트로 분리 가능
- 람다 함수 실행 작업 → 누군가 Invoke 할 때 마다 Lambda 함수가 몇번 활용되었는지 알 수 있다
- 람다 함수가 많이 실행되면볼륨이 커질 수 있음
CloudTrail Insights
- 계정마다 많은 이벤트와 API 호출이 이루어지기 때문에 무엇이 이상하거나 특이한지 파악하기 어렵다 → 이럴때 CloudTrail Insights를 사용
- 이벤트를 분석해서 계정 내의 특이한 활동을 탐지해준다
- 특이한 활동
- 부정확한 리소스 프로비저닝
- AWS IAM 작업 버스트
- 주기적 유지 관리 작업 부재
- 관리활동 분석해서 기준선을 생성한 다음 무언가를 변경하거나 변경하려고 시도하는 모든 것을을 지속적으로 분석해서 특이한 패턴을 감지한다
- 특이한 활동을 감지한다면 Insights Event로 생성
- s3, CloudTrail console 등으로 저장 가능

Event Retention(보존기간)
- 기본적으로 90일간 저장되고 이후 삭제
- 더 오래 저장하고 싶다면 s3로 전송해서 s3에 로그를 기록 Athena로 분석

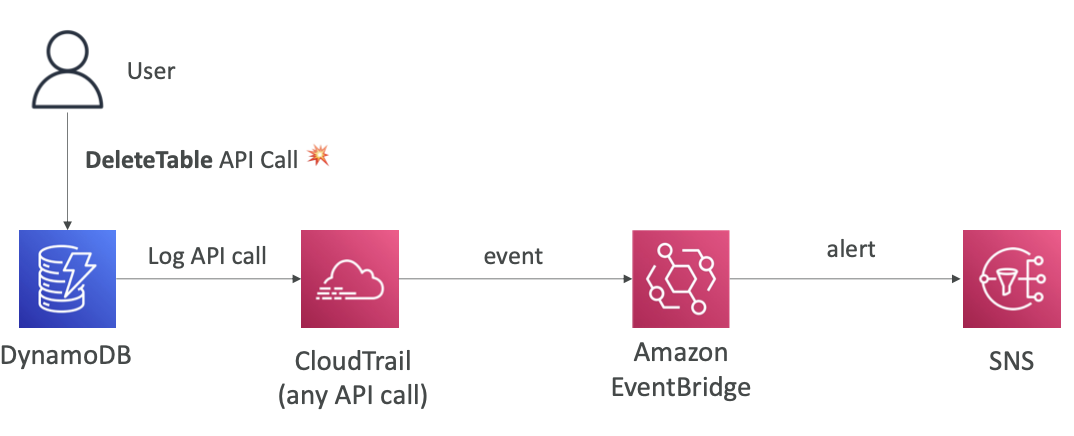
CloudTrail 통합 - Intercept API Calls
API 호출을 가로채는 EventBridge와의 통합을 알아두어야 한다
- 테이블 삭제 API 호출을 사용해서 테이블 삭제할 때마다 SNS 알림을 받고 싶을 때..
- 모든 API 호출이 CloudTrail로 로깅된다.
- 모든 API 호출은 EventBridge 이벤트로 기록된다
- 특정 테이블 삭제 API 호출을 찾아 규칙을 생성한 뒤 SNS로 알림
AWS Config
- AWS내 리소스에 대한 감사와 규정 준수 여부를 기록할 수 있게 해주는 서비스
- 설정된 규칙에 기반해 구성과 구성의 시간에 따른 변화를 기록할 수 있으며 필요한 경우 인프라를 롤백하고 문제점을 찾을 수 있다
- 보안 그룹에 제한되지 않은 SSH 접근이 있었는지
- 버킷에 공용 엑세스가 있는지
- 시간이 지나며 변화한 ALB 구성이 있는지
- 규칙을 준수하든 아니든 변경 여부 상관없이 SNS 알림을 받을 수 있다
- 리전별 서비스
- 데이터를 중앙화하기 위해 리전과 계정 간 데이터 통합 가능
- 리소스의 구성을 s3에 저장해 나중에 분석 가능(Athena)
AWS Rules
- AWS가 제공하는 관리형 규칙 혹은 커스텀 규칙(람다함수로 정의)이 있다
- EBS 디스크가 gp2 유형인지 평가 가능
- 개발 계정의 인스턴스가 t2.micro인지 평가 가능
- 몇몇 규칙들은 변경될 때마다 평가되고 트리거 혹은 스케줄해서 평가할 수 있음
Config 규칙은 규정 준수를 위한 것 → 어떤 동작을 미리 예방하거나 차단할 수 없다
보안같은 메커니즘이 아니며 구성의 개요와 리소스의 규정 준수 여부는 확인 가능
결제해야하며 굉장히 비싸질 수 있다
Config Resource
- 보안그룹의 규정 준수 상태확인 가능

- 리소스 구성도 시간별로 확인 가능(언제 누가 변경했는지)

- CloudTrail과 연결해 리소스에 대한 API 호출을 볼 수도 있다

일어나는 모든일을 전부 파악 가능
Remediations(수정)
SSM 자동화 문서를 사용해 규정을 준수하지 않는 리소스를 수정 가능
- IAM 엑세스 키의 만료 여부를 모니터링 (키가 90일 이상 보관된 경우로 규정 미준수)
- 규정 미준수를 예방하지 못하지만 미준수 할때마다 키를 비활성화 시키는 수정 작업을 진행할 수 있다
- 람다 함수를 실행하는 문서를 생성해서 원하는 작업을 수행 가능하며 재시도 할 수 있다
- 자동 수정했음에도 미준수한다면 5번까지 재시도 됨

Notifications(알림)
- EventBridge를 사용해 리소스가 규정을 미준수했을 때마다 알람을 보낼 수 있다
- 보안그룹을 모니터링하다가 규정 미준수 상태가 되면 EventBridge에서 이벤트를 트리거해 원하는 리소스에 넘길 수 있다

- 모든 구성 변경과 모든 리소스의 규정 준수 여부 알림을 Config에서 SNS로 보낼 수 있다
- 모든 이벤트가 Config를 통하지만 SNS 필터링을 사용해 특정 토픽만 알림받을 수 있다

CloudTrail vs CloudWatch vs Config
매우 자주 출제되는 문제 중 하나로 각각을 구분하는 것이 있다
CloudWatch
- 지표, CPU 네트워크 등의 성능 모니터링과 대시보드를 만드는데 사용
- 이벤트와 알림
- 로그 집계와 분석
CloudTrail
- 계정 내에서 사용된 모든 API 호출을 기록
- 특정 리소스에 대한 추적도 정의할 수 있다
- 글로벌 서비스
Config
- 구성 변경을 기록
- 규정 준수 규칙에 따라 리소스를 평가
- 변경과 규정 준수에 대한 타임라인을 UI로 보여준다
ELB를 통한 세 가지 모니터링 서비스를 분류
CloudWatch
- 들어오는 연결 수를 모니터링한다
- 오류 코드 수를 시간 흐름에 따라 비율로 시각화 할 수 있다
- 로드밸런서의 성능을 볼 수 있는 대시보드를 만들 수 있다
Config(규정을 만들고 잘 준수하는지)
- 로드 밸런성 대한 보안 그룹 규칙을 감시해 변경하지 못하게 하려고 사용
- 누군가 SSL 인증서 등을 수정하지는 않는지 확인
- 로드 밸런서의 구성 변경을 추적
- SSL 인증서가 로드밸런서에 항상 할당되어 있어야한다는 규칙을 만들어 암호화되지 않은 트래픽이 로드밸런서에 접근하지 못하게 할 수 있다
CloudTrail(누가 사용하거나 변경했는지 확인)
- 누가 API를 호출하여 로드밸런서를 변경했는지 추적
- 누군가 보안 그룹 규칙, SSL 인증서를 바꾸거나 삭제한다면 누가 했는지 확인 가능
'TIL > AWS' 카테고리의 다른 글
| AWS 보안 및 암호화 (0) | 2023.06.11 |
|---|---|
| Identity and Access Management(IAM) - 고급 (0) | 2023.06.09 |
| AWS 머신러닝 (0) | 2023.06.06 |
| AWS 데이터 & 분석 (0) | 2023.06.05 |
| AWS의 데이터베이스 (0) | 2023.06.05 |