Aurora ( 시험에 자주 나옴 )
어떻게 작동하는지만 이해하면 됨
- AWS에서 제공하는 고유의 기술로 Postgres와 MySQL DB와 호환된다
- 클라우드 최적화 RDS의 MySQL보다 5배 Postgres의 3배의 성능을 가진다
- 스토리지 자동 확장
- 10GB에서 시작하지만 자동으로 128TB까지 커짐 → 저장 공간을 신경쓰지 않아도 됨
- 최대 15개의 읽기 전용 복제본과 속도도 더 빠름
- 장애조치에 즉각적으로 반응하고훨씬 빠르며 가용성 또한 높다
- 비용은 RDS비해 20%정도 비싸지만 스케일링 측면에서 훨씬 효과적
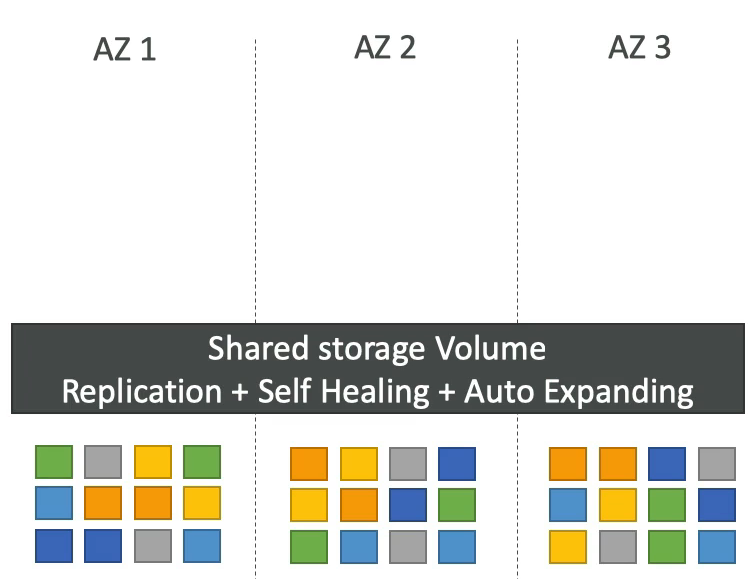
Aurora의 높은 가용성과 읽기 스케일링
- 3개의 AZ를 거쳐 무언가를 기록할 때마다 6개의 사본을 저장한다. ( 각 AZ별 2개 )
- 쓰기에는 4개 읽기에는 3개만 있으면 된다
- 데이터가 손상되거나 문제가 있으면 P2P 방식을 활용하여 자가 복제
- 수백개의 볼륨을 사용하여 리스크를 감소 시켜줌
- 다중 AZ와 유사하여 쓰기 작업은 마스터 하나만 받는다.
- 마스터가 응답하지 않으면 30초내에 복구 작업 시작
- 읽기 복제본을 최대 15개나 둘 수 있다. 이후 마스터에 문제가 생기면 읽기 복제본이 마스터의 역할을 수행
- 리전간 복제를 지원한다
- 마스터는 하나고 복제본은 여럿이며 스토리지가 복제 된다. 작은 블록 단위로 자가 복구 또는 확장이 일어난다
Aurora DB Cluster - Aurora의 작동방식
클라이언트가 있을 때 수많은 인스턴스와 어떻게 접속하는지
- 마스터가 수정될 수 있으므로 writer 엔드포인트를 제공
- 클라이언트는 Writer Endpoint로 마스터 베이스에 접근할 수 있다
- 읽기 전용 복제본을 자동 스케일링 설정하면 적절한 수의 복제본이 항상 존재할 수 있다
- 다만 앱 입장에서는 복제본과 URL, DB를 어떻게 연결하는지 파악이 어려울 수 있다
- 따라서 Reader Endpoint를 제공한다
- 커넥션 로드 밸런싱과 모든 읽기 전용 복제본과 자동 연결
- 로드 밸런싱은 연결 레벨에서 이루어진다

핵심 키워드
Writer Endpoint, Reader Endpoint, 자동 스케일링, 자동 확장되는 공유 스토리지 볼륨이다
Aurora 특징

앞서 봤던 여러 특성들과 Backtrack → 백업에 의존하지 않는 데이터 복구 기법이라고 한다.
실습
- Writer 인스턴스와 Reader 인스턴스가 따로 있고 엔드포인트 또한 따로 있어 항상 엔드포인트를 통해 애플리케이션이 인스턴스에 접근
- 사용량을 기준으로 해서 읽기 전용 복제본 자동 스케일링 가능
- Global Aurora를 통해 다른 리전에도 생성 가능


Amazon Aurora 고급 개념
복제본 자동 스케일링
- 리더 엔드포인트로 많은 요청이 들어오면 자동 스케일링 시킬 수 있다.
- 리더 엔드포인트는 자동으로 확대되고 자동으로 트래픽이 분산되어 사용량이 감소될 수 있다.

커스텀 엔드포인트
- 용량이 큰 인스턴스를 따로 커스텀 엔드포인트로 빼서 특정 쿼리를 처리할 수 있게 만든다
- 사용자 지정 엔드포인트를 만들면 리더 엔드포인트는 사용되지 않는다
- 워크로드에 따라 여러 엔드포인트를 만들 수 있음
Aurora Serverless
- 실제 사용량에 기반한 자동 데이터베이스 인스턴스화 스케일링
- 비정기적, 예측 불허한 워크로드에 적합하며 용량 계획을 세울 필요 없고, 초당 사용량으로 계산

Aurora Multi-Master
- writer 노드에 대한 즉각적 장애 조치로 writer 노드에 높은 가용성을 유지하고 싶을 때 사용
- Aurora 클러스터의 모든 노드에서 읽기 쓰기가 가능. 기존엔 하나의 노드만 있었다
- 하나의 노드에서 장애조치가 생기면 다른 노드로 넘어감
Global Aurora
- 리전간 복제본은 재해 복구에 많은 도움이 되며 만들기 쉽지만 최근에는 Global이 권장된다
- 하나의 기본 리전이 있다
- 복제 지연이 1초인 읽기 전용 복제본을 5개까지 설정 가능
- 각 보조지역마다 읽기전용복제본을 16개까지 생성 가능하며 읽기 전용 복제본의 지연시간을 감소시킬 수 있다
- 이후 문제가 생기면 다른 곳에 있는 읽기 전용 복제본이 Read/write 클러스터로 승격된다
- 다른 리전으로 복구하는데 1분도 걸리지 않는다
- Aurora Global 데이터베이스에서 리전에 걸쳐 데이터를 복제하는데 걸리는 시간은 1초 미만이다
- 시험에 이런 문장이 보이면 Global Aurora를 사용하라는 의미임

Aurora 머신러닝
- 머신러닝과 결합할 수 있고 AWS에서 제공하는 머신러닝 모델과 결합하기 쉽다
- 머신 러닝 경험은 필요하지 않고 기능에 따라 사용하면 된다
'TIL > AWS' 카테고리의 다른 글
| RDS & Aurora Security (0) | 2023.05.24 |
|---|---|
| AWS RDS 백업 (0) | 2023.05.24 |
| AWS RDS (0) | 2023.05.24 |
| AWS Auto Scaling Groups - 스케일링 정책 (0) | 2023.05.22 |
| AWS Auto Scaling Group (ASG) (0) | 2023.05.22 |